What Are Knowledge Graph Embeddings? A Beginner-Friendly Guide
Learn what knowledge graph embeddings are and how they help machines uncover relationships, improve predictions, and make smarter decisions.

Introduction
The way we store and connect information has evolved greatly. In many modern systems, from search engines and recommendation algorithms to digital assistants, knowledge graphs play a vital role. They organize data as a web of interconnected facts, where entities (like countries, people, or products) are linked through relationships (like capitalOf, friendOf, or purchasedWith).
But there’s a catch.
Most knowledge graphs are incomplete. They often miss important links or facts that haven’t yet been discovered or entered. This makes it hard for machines to draw accurate conclusions or make helpful predictions. For example, a system might not know that Bulgaria is in Europe simply because that connection hasn’t been added yet.
This is where Knowledge Graph Embeddings (KGE) come in.
In this guide, we’ll break down what knowledge graph embeddings are, how they work, and why they’re becoming essential tools in modern machine learning systems.
What Are Knowledge Graph Embeddings?
Knowledge graph embeddings are a way to turn the elements of a knowledge graph, such as entities (like Paris or Google) and relations (like capitalOf or foundedBy), into numbers. More specifically, each entity and relation is represented as a vector in a continuous, low-dimensional space.
This is useful because machines understand numbers better than symbolic text. Instead of just storing facts like "Paris is the capital of France," embedding models create mathematical representations that reflect these relationships. For example, in a model like TransE, the idea is that:
Paris_vector + capitalOf_vector ≈ France_vector
This mathematical structure allows the system to understand and work with relationships in a deeper way. Once these vectors are trained, they can help answer questions such as:
- What country is Paris the capital of?
- Which cities might be capitals but are not yet connected in the graph?
Why are these embeddings useful?
- They convert symbolic data into a machine-friendly format.
- They help machine learning models capture the meaning and similarity between entities and relations.
- They can be used to predict missing links or discover new patterns in the graph.
In simple terms, knowledge graph embeddings help turn complex webs of information into something that machines can process and reason over effectively.
Inspiration from Word Embeddings
The idea behind knowledge graph embeddings comes from an earlier success in natural language processing: word embeddings.
Word embeddings like Word2Vec made it possible to represent words as vectors. These vectors captured not just the identity of a word, but also its meaning and context. For example, in Word2Vec, the model learns that:
king - man + woman ≈ queen

This simple math showed how word vectors could reflect complex relationships.
Inspired by this, researchers began exploring similar methods for graphs. After all, a knowledge graph is just a different kind of structure, where entities (like "Barack Obama") are linked by relations (like "bornIn").
To bring these techniques to graphs, models like DeepWalk were introduced. DeepWalk treats the graph like a text document.

It generates random walks through the graph similar to sentences composed of entities, and then applies Word2Vec-style training to learn embeddings.
Later, node2vec improved this idea by using smarter random walks. Instead of just walking randomly, node2vec balances between exploring close neighbors and far-off parts of the graph. This makes the learned embeddings more useful in a wider range of tasks.
These early models focused only on the graph’s structure, not the specific types of relationships. But they laid the foundation for more advanced knowledge graph embedding models that came later.
Core Characteristics of KGE Models

Knowledge Graph Embedding models have a few essential characteristics that make them powerful tools for working with complex data:
1. Efficient Computation
KGE models transform large graphs into lower-dimensional vector spaces, which makes computations faster and more manageable. Instead of working with raw graph data, systems can use compact embeddings to perform tasks like classification, clustering, or link prediction much more efficiently.
2. Dimensionality Reduction
Graphs can be huge, with thousands or millions of nodes and edges. Embeddings reduce this complexity by mapping each element (entity or relation) to a vector in a fixed-size space. This keeps the size of the data under control while preserving the most important information.
3. Semantic Similarity
One of the biggest advantages of KGE is the ability to capture semantic meaning. Entities and relations that are similar or related in the knowledge graph tend to have embeddings that are close together in the vector space. For example, the embeddings for “Paris” and “London” might be close because both are capital cities with similar types of relationships to other countries and places.
4. Generalization Power
Once trained, KGE models can generalize beyond the data they were given. This means they can infer missing links, discover hidden patterns, and support reasoning across new or incomplete parts of the graph. That makes them especially useful for real-world applications like recommendation systems, search engines, and question answering tools.
Key Types of KGE Algorithms
Over time, researchers have developed different types of KGE algorithms, each with its own strengths. These can be broadly grouped into two main categories: translational models and semantic matching models.
1. Translational Distance Models

These models treat relationships in the graph as translation operations in vector space. The basic idea is that the vector of the head entity plus the vector of the relation should be close to the vector of the tail entity.
Examples:
- TransE: One of the simplest models. It assumes that head + relation ≈ tail. It works well for one-to-one relationships but struggles with more complex ones.
- TransH: Improves on TransE by allowing each relation to have its own hyperplane, making it better at handling many-to-many relationships.
- TransR: Takes it further by projecting entities into relation-specific spaces. This helps when the same entity behaves differently depending on the relation.
2. Semantic Matching Models

These models focus on learning compatibility between entities and relations using scoring functions or neural networks. Instead of simple vector translations, they evaluate how well entity-relation combinations match in a learned space.
Examples:
- DistMult: A simple model that scores triplets using multiplication. It's efficient but limited because it assumes all relations are symmetric.
- ComplEx: Extends DistMult by using complex numbers to handle asymmetric relations, making it suitable for more real-world scenarios.
- RESCAL: Uses matrices for relations and learns interactions between all dimensions of the entity vectors. It's powerful but can be computationally expensive.
- NTN (Neural Tensor Network): Combines tensors and neural networks to capture deep interactions, offering high expressiveness but requiring more resources.
These models serve as the foundation for many real-world applications and are often combined or extended to get better performance on tasks like link prediction and entity classification.
How Does It Work?
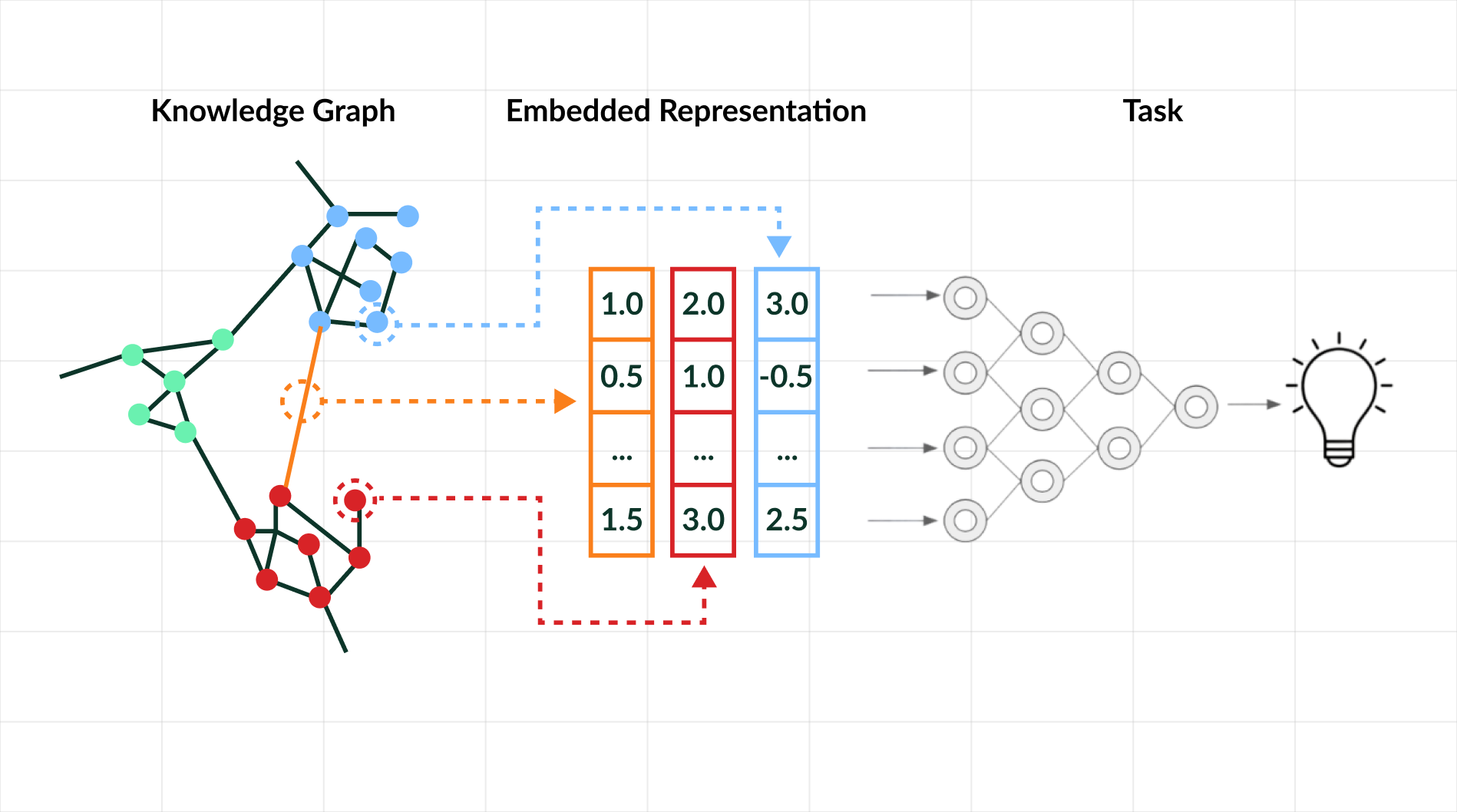
Knowledge graph embeddings work by converting entities and relationships into vectors in a low-dimensional space. The idea is that true relationships follow a pattern.
To understand it better, let’s look at one of the most popular models called TransE.
In a knowledge graph, information is stored as triples, for example, (Paris, capitalOf, France). TransE represents each entity and relation as a vector in a continuous space. The key idea is simple: if the triple is true, then the vector for the head entity (Paris), plus the vector for the relation (capitalOf), should be close to the vector for the tail entity (France).
Mathematically, this means:
head_vector + relation_vector ≈ tail_vector

Here’s how this helps:
- Each entity (like “Paris” or “France”) is mapped to a point in a low-dimensional space (a vector).
- Each relation (like “capitalOf”) is also a vector that acts like a translation connecting the head and tail vectors.
- The model learns these vectors so that for true triples, the above equation holds approximately.
For example, if the embedding vectors look like this:
- Paris = [1.0, 2.0, 3.0]
- capitalOf = [0.5, 1.0, -0.5]
- France = [1.5, 3.0, 2.5]
You can see that Paris + capitalOf is very close to France:
[1.0 + 0.5, 2.0 + 1.0, 3.0 - 0.5] = [1.5, 3.0, 2.5]
This shows the triple (Paris, capitalOf, France) is plausible according to the model.
The TransE model uses a scoring function to measure how close these sums are. During training, it adjusts the vectors to minimize the difference for true triples and maximize it for false ones.
By learning these embeddings, TransE makes it easier to work with knowledge graphs for tasks like predicting missing links, classifying entities, or powering recommender systems.
Tools and Libraries for Knowledge Graph Embedding
Working with knowledge graph embeddings often requires specialized tools and libraries that simplify the process of building, training, and evaluating embedding models. Here are some of the most widely used frameworks:
1. PyKEEN
PyKEEN is a popular Python library designed specifically for knowledge graph embedding. It offers implementations of many embedding models, such as TransE, DistMult, and ComplEx, and provides utilities for training, evaluation, and hyperparameter tuning. PyKeen is user-friendly and integrates well with PyTorch.
2. AmpliGraph
AmpliGraph is another Python library focused on knowledge graph embeddings. It supports multiple algorithms and is built on TensorFlow. AmpliGraph is useful for both research and production use, providing tools for training embeddings and performing link prediction or entity classification.
3. OpenKE
OpenKE (Open-source Knowledge Embedding) is a framework developed by researchers for implementing various KGE algorithms. It supports models like TransE, TransH, and ComplEx, among others. OpenKE is written in C++ and Python, making it efficient and versatile.
4. LibKGE
LibKGE is a flexible and modular toolkit for knowledge graph embedding research. It emphasizes extensibility, allowing researchers to easily add new models or customize existing ones. The library supports many popular embedding methods and offers comprehensive evaluation tools.
5. DGL-KE
DGL-KE is a high-performance library built on the Deep Graph Library (DGL) for large-scale knowledge graph embedding. It is optimized for speed and scalability, capable of handling very large graphs with millions of entities and relations, making it ideal for industrial applications.
Real-World Use Case: Link Prediction

One of the most practical applications of knowledge graph embeddings is link prediction. Link prediction involves identifying missing or potential relationships between entities in a knowledge graph. This is important because knowledge graphs, even when large, often have incomplete information, and predicting new links helps fill these gaps.
For example, in a knowledge graph representing countries and their relationships, you might have triples like (France, bordersWith, Germany) and (Germany, bordersWith, Poland), but the relationship (France, bordersWith, Belgium) could be missing. By using embeddings, a model can infer the likelihood of such missing links based on learned patterns.
How does this work? Once entities and relations are embedded into a continuous vector space, the model uses a scoring function to estimate the plausibility of potential triples. High scores indicate that the predicted link is likely to be true, while low scores suggest the opposite.
In practice, this can help:
- Suggest new connections in social networks
- Predict protein-protein interactions in biology
- Discover relationships in recommendation systems, such as suggesting products a user might like based on their past interactions
By automating the discovery of new links, knowledge graph embeddings enable systems to become smarter and more complete, improving the quality of information and recommendations offered.
Why Knowledge Graph Embeddings Matter
Knowledge graphs represent complex networks of information, but their symbolic and structured nature can make them difficult for traditional machine learning models to use directly. Knowledge graph embeddings address this challenge by converting graph elements, entities, and relationships into continuous vector representations that machines can process efficiently and effectively.
This transformation has several important benefits:
- Simplifying Complex Data: Embeddings reduce the complexity of large, interconnected graphs into manageable numerical formats, enabling easier analysis and computation.
- Improving Machine Learning Performance: By capturing semantic meanings and structural patterns, embeddings enable machine learning models to understand relationships in data more deeply, leading to more accurate predictions and insights.
- Enhancing Search and Recommendations: Embeddings enable smarter search algorithms and recommendation systems by identifying subtle connections between items, users, or concepts that may not be obvious from explicit data alone.
- Discovering Hidden Patterns: Embeddings help uncover relationships or clusters within the data that were previously unknown, thereby supporting knowledge discovery and innovation in fields such as healthcare, finance, and social networks.
Overall, knowledge graph embeddings are a powerful tool for bridging the gap between symbolic knowledge and numerical machine learning, driving smarter and more efficient applications across various domains.
Conclusion
Knowledge graph embeddings have transformed the way we represent and analyze complex relational data. By converting entities and relationships into continuous vector spaces, these models unlock hidden insights, improve prediction accuracy, and power advanced applications such as recommendation systems, intelligent search, and question answering.
As knowledge graphs continue to expand in scale and complexity, embedding techniques will evolve alongside them, offering increasingly powerful tools to help businesses and researchers extract deeper value from their data.
If you're exploring ways to leverage knowledge graph embeddings for smarter AI solutions, KnackLabs can help. Our team specialises in building enterprise-grade AI applications tailored to your needs. Get in touch to learn how we can support your next breakthrough.
FAQs
What is knowledge graph embedding?
Knowledge graph embedding is a technique that transforms entities and relationships in a knowledge graph into continuous vector representations. These embeddings convert complex symbolic data into numbers that machines can process, making it easier to analyze, predict missing links, and discover patterns in the graph.
How do embeddings in machine learning help with knowledge graphs?
Embeddings in machine learning provide a way to represent graph elements as vectors in a low-dimensional space. This helps algorithms capture semantic meaning and structural information, enabling tasks like link prediction, classification, and recommendation with higher accuracy and efficiency.
What is the difference between graph embedding and knowledge graph embedding?
Graph embedding is a broad term for representing nodes, edges, or subgraphs from any graph (e.g. social or citation networks) as vectors. Knowledge graph embedding focuses specifically on semantic graphs, embedding both entities and labeled relations to preserve meaning and enable symbolic reasoning.
Can you explain how a simple knowledge graph embedding model like TransE works?
TransE represents entities and relations as vectors in a continuous space. It models a relationship as a translation from the head entity vector to the tail entity vector. In other words, the vector of the head entity plus the vector of the relation should be close to the vector of the tail entity. This helps the model learn and predict valid triples.
What are common applications of knowledge graph embeddings?
Knowledge graph embeddings are widely used for:
- Link prediction to find missing relationships
- Recommendation systems to suggest relevant items
- Question answering by understanding entity relationships
- Entity classification and clustering
- Enhancing search engines with semantic understanding
What tools and libraries are available for working with knowledge graph embeddings?
Popular tools include PyKEEN, AmpliGraph, OpenKE, LibKGE, and DGL-KE. These libraries provide implementations of various embedding algorithms, utilities for training and evaluation, and support for large-scale graphs.
Why do knowledge graph embeddings matter in modern machine learning?
They matter because they bridge the gap between symbolic knowledge (facts and relationships) and numerical machine learning models. This allows machines to reason over complex data structures, improving predictive accuracy and enabling new AI-powered applications.

Get Smarter About AI in 5 Minutes a Week.
No jargon. No fluff. Just practical insights from businesses that are already making AI work for them.